




By Andrea Carraro and Stefano Armenes
An experiment with OpenAI tools
At NearForm, we have been experimenting with OpenAI tools for some time. ChatGPT and its APIs have been a particular focus, as we seek new ways to improve our efficiency and productivity and explore new patterns that could become part of our daily routine in the near future.
In this blog post, we are going to show how we created a ChatGPT Slack chatbot that can respond to questions regarding information stored on a proprietary knowledge base.
At NearForm, we have an internal Notion space where we capture all of our internal policies. The aim of the project covered in this blog post is to make it available via Slack, which is the instant messaging app we use internally.
Any user should be able to ask questions to the Slack chatbot and get back the relevant answer in natural language. The challenge is that ChatGPT doesn’t know anything about NearForm and its policies, therefore we needed a way to teach ChatGPT that information.
The code that we wrote to make this possible is available on GitHub.
Continue reading to learn more about our experience of developing ChatGPT-powered tools and how you can build one yourself!
The basic setup
In order to get up and running quickly, we followed the approach described in the OpenAI official docs.
Given two inputs:
Source content: the textual data we want ChatGPT to be able to answer questions about
A question sent by a user via Slack
Our problem was: how do we get a Slack bot to answer that question? The diagram below shows how it works at a high level:

Because our Notion space is quite large, we needed to reduce its size so that only a subset of that information relevant to the question was used to generate an answer. This subset is called context and this is what we are going to provide to the OpenAI API to generate an answer for us. Let’s see how to do it.
Generating embeddings
This step generates relevant embeddings for both the source contents and the question. Embeddings represent the semantic and syntactic relationships between words, allowing the model to recognise semantically similar inputs. They consist of vectors of floating-point numbers.
Once the source content text is collected and organised in pages, the relevant embeddings are generated via the create embeddings API to obtain a data frame similar to the following:
| text | embeddings |
| Page 1 content lorem ipsum | [-0.010027382522821426, -0.007285463623702526, ...] |
| Page 2 content lorem ipsum | [-0.009962782263755798, 0.000872827556083126, ...] |
| Page 3 content lorem ipsum | [-0.0076012867502868176, 0.0008478772360831499, ...] |
The same process is applied to the question, thereby generating the question embeddings.
Creating the context
Subsequently, source embeddings are ordered by their semantical proximity to the question embeddings and the most relevant ones are collected in a list. We are going to call this list context. OpenAI’s libraries provide specific utilities to do this calculation which is a plain cosine similarity calculation between two vectors.
Responding to the question
The question, along with instructions to ChatGPT about how to respond, as well as the previously generated context, is then supplied to the ChatCompletion API, which uses one of the available OpenAI models to generate an answer.
How we built our Node.js ChatGPT-powered Slack bot
To get started, we followed the instructions provided by the OpenAI tutorial about answering questions from a custom data source. We ended up with the following architecture, fully implemented in Node.js and running on Google Cloud Platform.
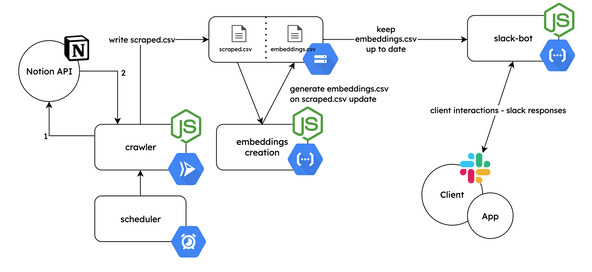
The project consists of 3 main components communicating with each other. The components are designed to be deployed as cloud functions on Google Cloud Platform:
Crawler: fetches the source content from Notion at scheduled intervals, and stores the results as a CSV file (named
scraped.csv) on a Google Cloud Storage bucket.Embeddings creation: generates the relevant source embeddings based on the crawler’s output using OpenAI APIs. Generated source embeddings are stored as a CSV file (named
embeddings.csv) in the same bucket.Slack bot: implements a Slack bot which generates answers from a question using the source content, source embeddings and ChatCompletion OpenAI API.
Crawler
This cloud function gets called once a day by a cloud scheduler. The function retrieves the text content from NearForm’s internal Notion space using notion-sdk-js, which then gets filtered, processed and saved to a scraped.csv file in a Google Cloud Storage bucket with the following structure:
| index | title | text |
| 0 | Page 1 title | Page 1 content lorem ipsum |
| 1 | Page 2 title | Page 2 content lorem ipsum |
| 2 | Page 3 title | Page 3 content lorem ipsum |
Embeddings creation
This cloud function is triggered each time a new scraped.csv is created. It enhances scraped.csv data by generating the relevant embeddings for the content of each page.
The Google Cloud function is executed when a cloud event is triggered (in this case scraped.csv file getting updated):
import * as ff from "@google-cloud/functions-framework";
async function createEmbeddings(event) {
const data = event.data;
const changedFile = data.name;
if (changedFile !== "scraped.csv") {
return;
}
// Here follows embeddings creation
}
ff.cloudEvent("create_embeddings", createEmbeddings);
… since we want to execute the function when the crawler updates the scraped.csv file, we will deploy to gcloud by providing a --trigger-bucket option:
gcloud functions deploy create_embeddings \
--trigger-bucket=YOUR_STORAGE_BUCKET \
...
Once we fetch the new scraped.csv, we are all settled to evaluate the embedding of each page content with create embeddings OpenAI API:
import fs from "node:fs/promises";
import { Configuration, OpenAIApi } from 'openai'
import { createCsv, parseCsv } from "./utils.js";
const openai = new OpenAIApi(
new Configuration({
apiKey: process.env.OPENAI_API_KEY
})
)
// Fetch scraped.csv file from storage bucket with '@google-cloud/storage'
// ...
// Parse scraped.csv
const dataFrame = await parseCsv((await fs.readFile("scraped.csv")).toString());
// Iterate over dataFrame and get the relevant embeddings for each entry
const embeddingResponses = await Promise.all(
dataFrame.map(({ text }) =>
openai.createEmbedding({
model: "text-embedding-ada-002",
input: text,
})
)
);
// Append embeddings value to original dataFrame
const embeddings = dataFrame.map((content, index) => ({
...content,
embeddings: embeddingResponses[index].data.data[0].embedding,
}));
// Parse dataFrame back to csv format
const embeddingsCsv = await createCsv(embeddings);
// Upload embeddingsCsv to storage bucket with '@google-cloud/storage'
// ...
The result gets stored back to the bucket as a embeddings.csv file with the following data frame:
| index | text | n_tokens | embeddings |
| 0 | Page 1 content lorem ipsum | 5 | [-0.010027382522821426, -0.007285463623702526, …] |
| 1 | Page 2 content lorem ipsum | 5 | [-0.009962782263755798, 0.000872827556083126, …] |
| 2 | Page 3 content lorem ipsum | 5 | [-0.0076012867502868176, 0.0008478772360831499, …] |
Since OpenAI API has a limit on the maximum number of input tokens for embeddings, the actual implementation turned out to be (sensibly) more complex than the provided examples as it was necessary to:
Split the content of larger pages into multiple lines
Limit the number of concurrent network requests issued to OpenAI while fetching the embeddings to avoid hitting rate limits
Handling possible OpenAI API failures and rate limit errors
Slack bot
The Slack bot is a cloud function which uses Slack’s Bolt to interact with Slack. Bolt is the official Slack SDK for subscribing to Slack events and provides the tools to build and integrate applications with the Slack platform.
This is how you set up a basic Slack bot with Bolt:
import bolt from "@slack/bolt";
const { App } = bolt;
const app = new App({
token: process.env.SLACK_BOT_TOKEN,
signingSecret: process.env.SLACK_SIGNING_SECRET,
});
app.event("message", async ({ event, client }) => {
const question = event.text;
const answer = "Your generated answer";
await client.chat.postMessage({
channel: event.channel,
text: answer,
});
});
Once a question is received, we need to generate the relevant answer with ChatGPT.
The next 2 steps consist of:
Generating the question embeddings (again with create embeddings OpenAI API)
Evaluating the distance of each previously generated content embeddings (
embeddings.csv) from the question embeddings
import { Configuration, OpenAIApi } from "openai";
import cosineSimilarity from "compute-cosine-similarity";
function distancesFromEmbeddings({ queryEmbedding, embeddings }) {
return embeddings.map((embedding, index) => ({
index,
distance: 1 - cosineSimilarity(queryEmbedding, embedding),
}));
}
const openai = new OpenAIApi(
new Configuration({
apiKey: process.env.OPENAI_API_KEY,
})
);
const response = await openai.createEmbedding({
model: embeddingModel,
input: question,
});
const queryEmbedding = response.data.data[0].embedding;
const distances = distancesFromEmbeddings({
queryEmbedding,
embeddings: contentEmbeddings, // These are the content embeddings generated before
});
The contents → question distance is evaluated as cosine similarity and returns a distance of each content embeddings entry from the question:
| 0.201678 |
| 0.137180 |
| 0.172750 |
With the distances in place, we can get the subset of the most relevant textual context by picking the source content entries with the smallest distance from the question:
| Most relevant page content |
| Second most relevant page content |
| Third most relevant page content |
Finally, we can interact with the ChatCompletion OpenAI API to generate an answer. To do so we instruct the AI in plain English, providing:
The information context just created
The instructions for the assistant
const response = await openai.createChatCompletion({
messages: [
{ role: "system", content: "You are a helpful assistant" },
{
role: "assistant",
content: `We are going to call the following set of information <CONTEXT>:\n\n${context.join(
"\n\n###\n\n"
)}`,
},
{
role: "assistant",
content: `If question is NOT related to <CONTEXT> or NearForm respond with: "I'm sorry but I can only provide answers to questions related to NearForm."`,
},
{
role: "assistant",
content: `If there is NO relevant information in <CONTEXT> to answer the question, then briefly apologize with the user.`,
},
{
role: "assistant",
content: `If you provide an answer, use only the information existing in <CONTEXT>. You must not use any other source of information."`,
},
{
role: "user",
content: `Question: ${question}`,
},
],
temperature: 0,
top_p: 1,
model: "text-embedding-ada-002",
});
Once you get your first response, you might consider adjusting the output by fine-tuning the provided instructions and API parameters such as temperature and top_p.
Porting from Python
JavaScript and its ecosystem is core to our expertise. However, we initially implemented the whole solution in Python, primarily to get an idea of what the proposed Python library ecosystem consists of and possibly to replicate it in Node.js. Besides our initial concerns, the port turned out to be quite straightforward. Here are the highlights.
OpenAI provides equivalent official Python and Node.js libraries to deal with their APIs. The developer experience is similar across the two libraries.
NumPy was originally used to handle vectors. We decided to opt for native JavaScript arrays. We might reconsider this option in case we come across performance issues or more advanced needs.
Pandas was originally used to convert from and to CSV and manipulate the generated data frames. We decided to use native JavaScript array transformation methods. The most complex scenario we needed to handle was a set of two-level nested arrays and large arrays of floating numbers, which was easy to address with native arrays.
Here is an example of how the default data set is fetched and parsed in both versions:
# Original Python implementation
import pandas
import numpy
dataSet = pandas.read_csv(local_embeddings_file, index_col=0)
dataSet["embeddings"] = dataSet["embeddings"].apply(eval).apply(numpy.array)
// Node.js port
import fs from 'node:fs'
import { parseCsv } from './utils.js'
const csv = fs.readFileSync(localEmbeddingsFile).toString()
const dataSet = await parseCsv(csv)
distances_from_embeddings was replaced with the npm package compute-cosine-similarity. The original distances_from_embeddings implementation supported several different distance metric options which we didn’t need for the scope of the project.
Conclusions
Beyond the small scope of application of this specific bot, it was clear early on how ChatGPT allowed us to accomplish a task that we didn’t deem possible before.
A simplistic approach, like the one taken in this project, seems to be good enough to scale to thousands of different fields of applications and (sensibly) to wider content sources.
In the meantime, several commercial solutions have been released (Sidekick, FAQ BOT and Amity Bots Plus) and the growing OpenAI APIs are unlocking scenarios and use cases which are now just a few keystrokes away from our fingers.
On a funny note, ChatGPT also actively contributed to this project’s codebase when we found ourselves stuck over a piece of Python code we couldn’t get to work and couldn’t find documentation about.
It’s been amazing to learn firsthand how much AI can do to make information retrieval easier and faster, and we are going to keep researching and experimenting in this space to see where this will lead us.