


Designing a Cloud-based Architecture With Infinite Scalability for an Elastic IPFS Provider


What is IPFS?
Interplanetary File System (IPFS) is a completely decentralized file-sharing network protocol. It’s designed to preserve and grow humanity’s knowledge by making the web upgradeable, resilient, and more open.
The lack of central authority and control poses some challenges in making the newly uploaded data immediately and always available.
In this article, we will show how we designed a cloud-based architecture which is seen from the rest of the IPFS peers as a single entity, but is actually a complex system with virtual infinite horizontal scalability and, thus, availability.
Requirements
The challenge our client wanted us to solve was not easy at all. The required system had to be able to serve an infinite amount of data to an infinite number of peers. So, an ‘infinite’ scalability was the main requirement.
As an additional feature, new nodes should be able to ramp up quickly as requests could spike up at any time.
Finally, in order not to break the democratic contract of the IPFS stack, the architecture would have to be reasonably affordable and reproducible by anyone, so that no overtaking of the network was possible for a single actor.
Architecture
The architecture we proposed was, for simplicity, tailored against AWS services, but it can be easily and quickly adapted for other cloud providers or even deployments for on-premise clusters.
In the early stages of our analysis we immediately realized that the system performed two main activities to which we assigned a subsystem: ingestion (Indexing Subsystem) of the data and serving the data to the connected peers (Peer Subsystem).
After some development, when integrating with other parts of the IPFS stack, we realized that we cannot exactly behave as a regular IPFS peer which would directly connect and advertise content using the Kademlia’s Distributed Hashtable (DHT) specification.
The incompatibility comes from the fact that the Elastic Provider is seen from the connected peers as a single host with a single PeerID.
As we show in the sections below, the provider ingests new content using multiple concurrent nodes and this would result in multiple connections being opened to the same peers from different sources. This configuration is not supported by the Kademlia DHT.
We thus adopted delegate content routing by sending data to the storetheindexsystem using HTTP protocol.
The final version of the architecture is composed of the following subsystems:
Indexing Subsystem: it validates and ingests new data for the Peer Subsystem and it enqueues the data to be later advertised by the publishing system.
Publishing Subsystem: it publishes data as available to the storetheindex system.
Peer Subsystem: it serves the data to the remotely connected peers using BitSwap protocol reading from the same DynamoDB tables and S3 buckets accessed by the Indexing Subsystem.
All the subsystems will be analyzed in detail in the sections below.
The Indexing Subsystem and resuming considerations
The Indexing Subsystem was implemented by leveraging AWS Lambda features, using S3 and DynamoDB as data storage.
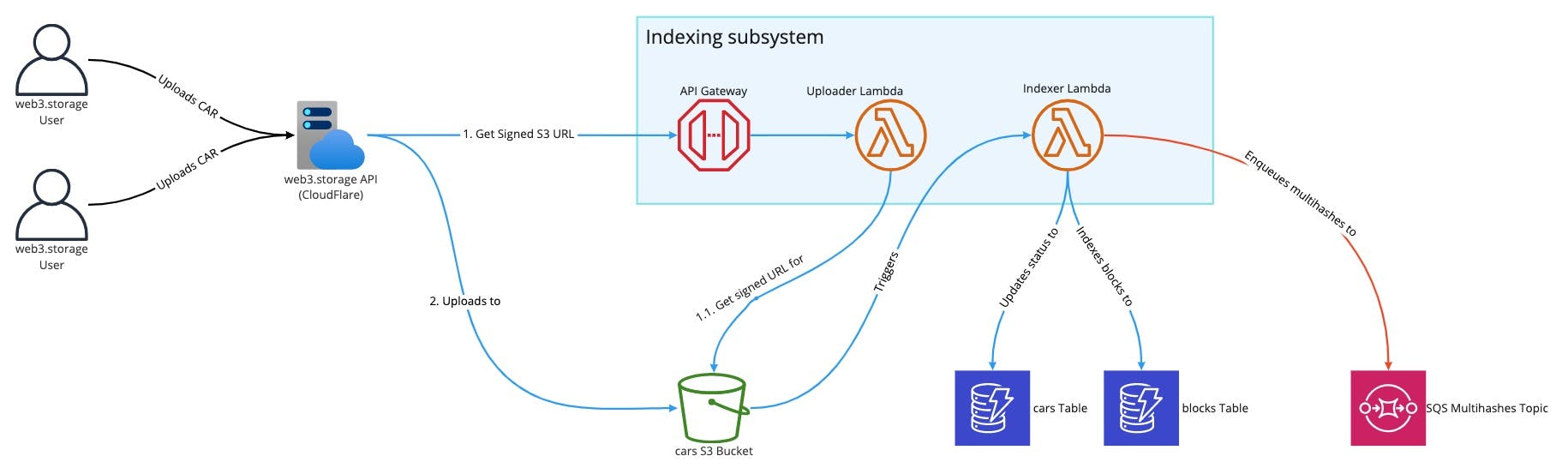
As soon as a CAR file is uploaded to IPFS via web3.storage API, the file is copied to an S3 bucket and this creates an entry in an SQS topic. The Indexing Lambda is configured to use this SQS topic as an event trigger.
Upon starting, Lambda starts streaming the file (leveraging the fact that the CAR format is optimized for sequential parsing) and validates the format.
For each data block found in the CAR file the function saves the block type, offset and length in the Blocks DynamoDB table. The record also contains the list of all CAR files the block was found into. The multihash of the block, which is a universally unique identifier for the block itself, is enqueued in an SQS Topic which will later be accessed by the Publishing Subsystem.
At the same time, the Lambda also stores the progress in the CAR file (represented as the byte offset of the last analyzed block in the file) in another DynamoDB table.
The reason for storing CAR file indexing status is not solely for tracking progress on other systems or to report to the user. One very interesting aspect of the CAR file is that the parsing complexity is not given by the file size but from the number of blocks inside the file.
When a CAR file is the representation of big archive files (e.g. a ISO image), the number of blocks in the file will be roughly the total file size in KB divided by 256 (which is the typical raw block size). As the indexer does not have to read the entire raw block but only the block head (which is only a few bytes), parsing and indexing will be really fast.
When the CAR file is instead made of a lot of very small files (e.g. an Ethereum transactions log), the CAR file can contain millions of blocks even if the overall file size is relatively small (hundred of MBs). In that case the parsing and indexing will be really slow because the impact of database writes (which are network-close but not machine-local) becomes really relevant.
In the latter case, it’s very easy to fail to process a file in the maximum time allowed by AWS Lambda (15 minutes). Also, in case of errors, it would be extremely penalizing to have to start indexing from the start of the file.
Thus, we track and update the status of each CAR file analyzed at the end of each block and the Indexing Lambdas are able to resume the indexing exactly where the previous run left it.
Publishing Subsystem and throughput optimization
The Publishing Subsystem is responsible for letting the storetheindex indexer nodes know that new data is available in the Elastic Provider. This is accomplished by performing the following three steps, which involve manipulating DAG-JSON encoded files:
Create and upload to S3 a new advertisement’s contents file which lists all the new available multihashes.
For each new advertisement’s contents file, create and upload to S3 a new advertisement file, which contains a link to the file produced in the previous step and a link to the previously last created advertisement file.
Update and upload to S3 the head file which contains a link to the last created advertisement file in the previous step. This file is used by storetheindex nodes to iteratively synchronize the queue up to the last synced advertisement.
The S3 bucket used in these uploads is configured as a publicly readable bucket. This means that when the storetheindex system wants to fetch those files it can directly query S3 via HTTP without an additional web server required.
What might not be immediately easy to see is that all the steps below cannot be performed in a purely concurrent execution context using independent workers. This would result in a race condition, as two workers publishing new advertisements at the same time and then modifying the head link will result in data loss. This is since only one update can become the new head and thus the other worker’s update will be excluded from the link chain.
To avoid this problem, the designed architecture uses a two-step SQS-Lambda chain that performs a map-reduce operation.
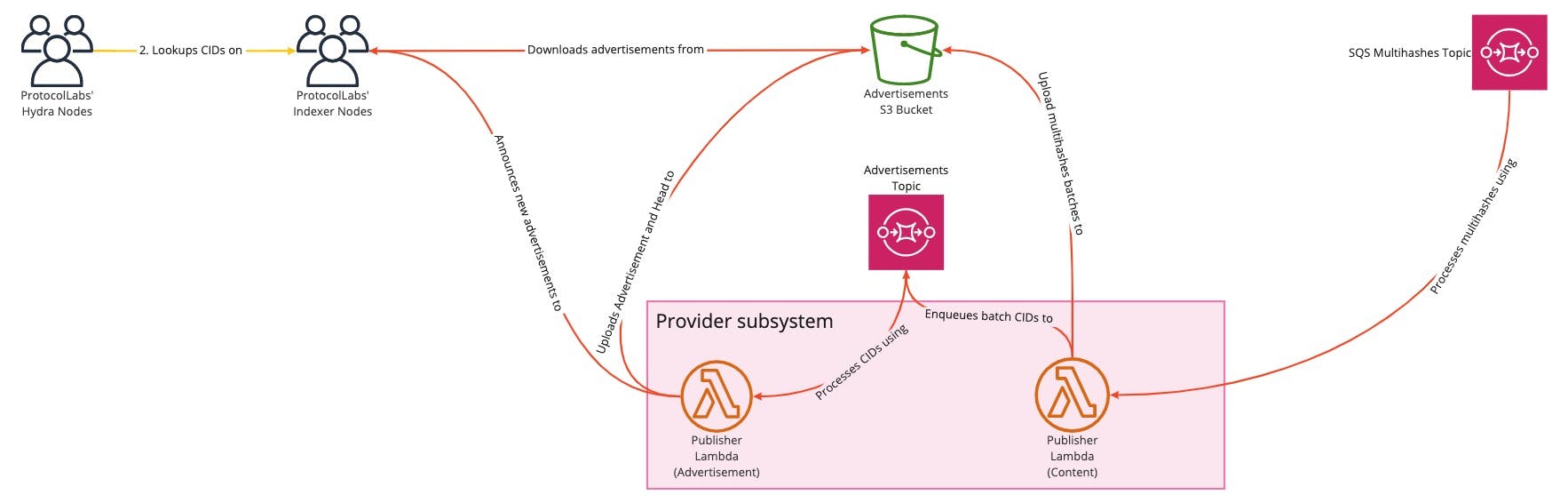
The first Lambda, called the Content Lambda, receives multihashes batches from the multihashes SQS topic with a maximum size of 10,000 (limit imposed by AWS). All these multihashes are uploaded to S3 as a single advertisement content file. The file’s Content ID (CID) is then enqueued to the Advertisements Queue. The Content Lambda has no maximum concurrency set. This is the map operation.
The second Lambda, called the Advertisement Lambda, reads from advertisements SQS topics and, for each advertisement CID publishes, uploads the new advertisement file to S3, linked to the previous one. At the end of the batch, it also updates the link of the head of the queue. This is the reduce operation.
The Advertisement Lambda has a maximum concurrency of one (so no concurrent execution) and this resolves the race condition. Thanks to the batch size allowed by Lambda the system is able to vastly reduce the number of updates on this step.
The system was designed with the target throughput of a billion of multihashes uploaded per day. With a reduction factor of 10,000 on each step, this results in 1,000 invocations of the Content Lambda and a single invocation of the Advertisement Lambda. Of course, in practice there are more invocations, as the limit above is theoretical, but real numbers do not differ a lot.
Peer Subsystem and stateless benefits
The Peer Subsystem is a cluster which exposes itself to the peers as a single machine.
This posed some challenges, especially when dealing with the BitSwap specification.
Thanks to the very specific requirements of the provider system, we were able to make some assumptions which allowed us to design a horizontally scalable system.
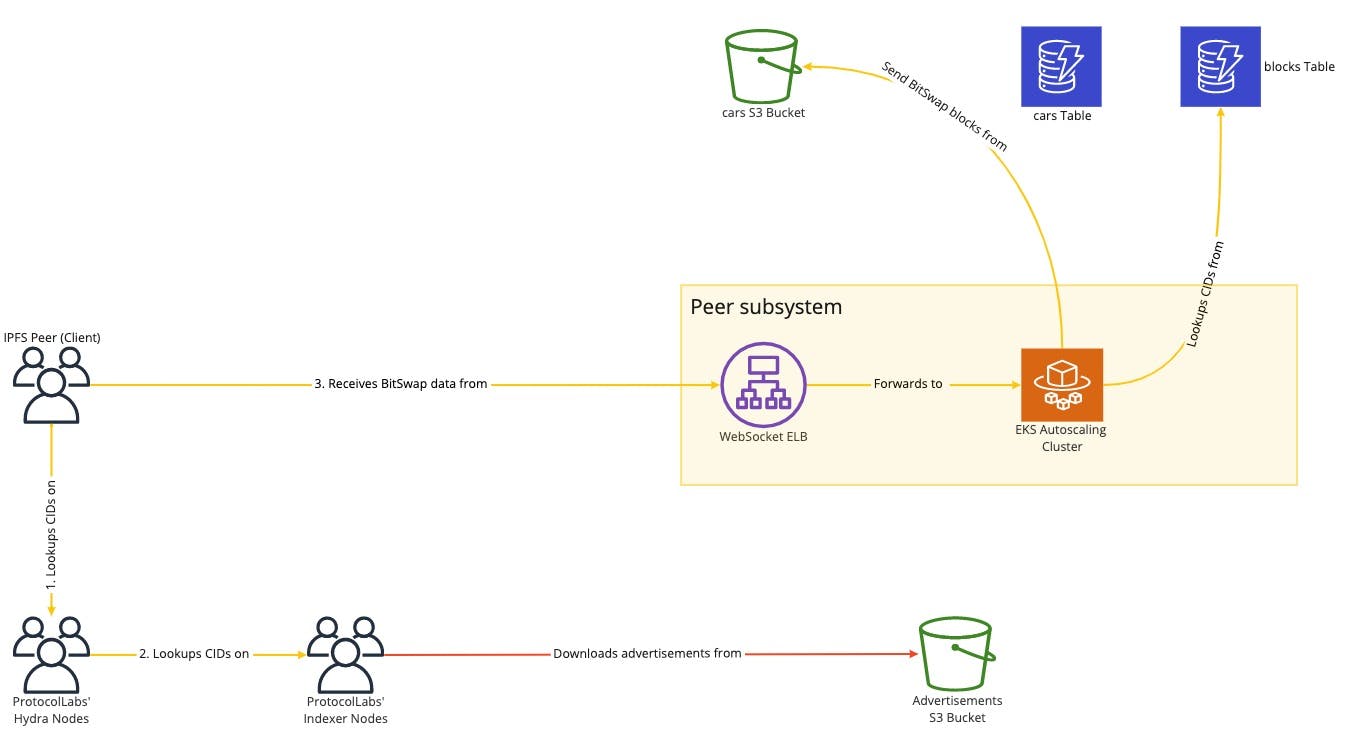
The resulting system is an EKS autoscaling cluster with an Elastic Load Balancer on front.
Clients connect via BitSwap protocol (which uses WebSockets) and the load balancer assigns the connection to a node.
Since the provider is only supposed to serve contents previously uploaded through the web3.storage system, there was no need for want lists or want managers as specified in the BitSwap specification. The system at any stage is able to immediately send content to the remote peer or reply with negative replies when the content has not been found.
The Peer Subsystem was inherently read-only and thus it only had to access the blocks DynamoDB table, which contains the indexes written by the Indexing Subsystem.
Once the data was found, a Byte-Range scoped request was made to S3 (using offset and length information stored in DynamoDB) and the data was forwarded to the client.
Given that there was no local node state, the system is able to add and drop nodes at any stage with no startup phase. This greatly improves the availability and scalability of the service.
Improve concurrency by using undici and HTTP pipelining
When initially measuring performance of the Peer Subsystem, we compared the performance against the Go IPFS client. The idea was to serve the same list of blocks using both systems and measure the total time.
Initially, we used a naive approach, which used `p-map` to process requests in parallel. The results were not really promising. The Go implementation was serving files in around 3 seconds, while our system took 13 seconds.
We knew that Go was reading blocks from the local filesystem and therefore we could probably never match its performance. But we were aiming to be around the 200%-250% slower range.
We made several attempts to improve performance but nothing was really promising, until we realized that DynamoDB and S3 talk using HTTP.
So we tried to leverage already existing features of the HTTP (in particular the pipelining feature) to overcome limitations given by DynamoDB.
We switched to making up to 100 requests on each Node.js event loop’s iteration without imposing a limit on the maximum of pending requests. As a client, we switched to undici and we carefully set the ‘connections’ and ‘pipelining’ options. The latter one was the game changer, as it maximized the network usage and thus the throughput. The Peer Subsystem execution time went down to 7 seconds, exactly in our target range.
But we didn’t stop there. We made an additional effort to offload all crypto-related operations (which are CPU intensive and thus block the Event Loop) to worker threads using piscina. This improved performance even more, reducing execution time to 3 seconds, exactly like the native Go IPFS implementation.
Results and final considerations
This architecture has been a challenge to us, but we were able to design a flexible and very well performant system by carefully analyzing the requirements and the tool we had.
As outlined earlier, even if the system is based on AWS and is technically cloud agnostic, all you need is a cloud or on-premise system made of the following components:
Shared database and file storage system
Queue system
Serverless computing system
A Docker-based cluster with auto-scaling capability
Apart from the system design itself, the main outcome of this project is that in order to design complex and resilient architecture you need to have extensive knowledge of the tools and protocols you want to use, including their limits (like the 10,000 maximum batch size in SQS).
Also, there are golden tools, protocols or techniques which can resolve all problems. You have to carefully analyze each choice you make and then be ready to make compromises on each.
Would your business benefit from our cloud expertise? Get in touch
At NearForm, we’re always keen to use our cloud expertise to help businesses achieve their goals. If your company is in need of a technical partner then contact NearForm today, we’d love to talk about how we can help you.